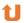SELECT * FROM test.movie where tag regexp "[[:< :]]ega[[:>:]]";
___
■ 大文字.小文字
大文字小文字区別
MySQLは特に指定がなければ大文字小文字は区別しません。
区別するには BINARY 属性をつける。
単語 境界
SELECT * FROM `posts` WHERE `name` = BINARY'hoge';
SELECT * FROM `posts` WHERE `name` = BINARY 'hoge';
SELECT * FROM `posts` WHERE `name` = BINARY 'hoge';
SELECT * FROM `posts` WHERE name = BINARY 'hoge';
alter table テーブル add unique (フィールド);
alter table test.art add unique (path);
___
■ Tutorial
___
■ copy
mysqlで、テーブルをコピーするには
mysqlで、テーブルをそっくりそのままコピーするには、今まで、下記のようなかたちでコピーしていました。
CREATE TABLE NewTable AS SELECT * FROM OldTable
use test; CREATE TABLE movie AS SELECT * FROM art;
これだと、主キーやインデックスなどはコピーしてくれません。
そこで、ちょっと調べました。
ちゃんとテーブル構造すべてをコピーしてくれるコマンドがあるんですね。
CREATE TABLE newtable LIKE oldtable
CREATE TABLE test.cook LIKE test.home;
echo "CREATE TABLE test.music LIKE test.movie"
CREATE TABLE test.home LIKE test.movie
とりあえず. insert してみる. -> 初動をクリアすること.
1.
INSERT INTO new SELECT * FROM old
TRUNCATE TABLE TableName;
___
■ ファイル 読み込み
SYNTAX
LOAD DATA INFILE file INTO TABLE tbl
DESC
ファイルから読み込むには LOAD DATA ステートメントを使う
csv ファイルを読み込みもできる
-- CREATE TABLE の順番でならべる
-- デフォルトは tab 区切り
name age
foo 10
bar 11
// 追加
insert into tbl (col1, col2...) values(val1, val2...)
// クエリ
select col from tbl where cnd
/// 更新
update from tbl where cnd
// 削除
delete from tbl where cnd
// RET
Connection id: 33
SSL: Not in use
Using delimiter: ;
Server version: 5.1.41-community MySQL Community Server (GPL)
Protocol version: 10
Connection: localhost via TCP/IP
Client characterset: utf8
Server characterset: utf8
TCP port: 3306
Uptime: 2 hours 28 min 37 sec
SYNTAX
SELECT field[, field...] from tbl [where field=val][ORDER BY field (DESC|ASC)][LIMIT [offset,] row_count]
DESC
テーブルからレコードを取得( 照会 )する
CustomerID、CompanyName は、それぞれ列( Key )の名前を指定
「Customersテーブルから
CustomerID、CompanyNameを取得しなさい」という命令になる
WARNING
SELECT 構文では 各節 ( where など )の順番は構文とおりの順番である必要がある
// BAD
select name LIMIT 1, 10 ORDER BY name
// OK
select name ORDER BY name LIMIT 1, 10
// すべての Column を指定
SELECT * FROM Customers
// 顧客 Table を表示する.
SELECT * FROM customer;
// Column を指定する { name, age }
SELECT name, age FROM Customer;
// 複数の条件を指定する.
SELECT * FROM Customer where name="sato" and age=30;
// 条件 >= , < = を利用する
SELECT * FROM Customer where age >= 30;
// 指定リストに一致するものを抽出
SELECT * FROM Customer where name in ( "tanaka", "sato" );
// あいまい 検索
// %: 0 文字以上の任意の文字
// _: 1 つの任意の文字
SELECT * FROM Customer where name like "%田%"
// 文字列も 順序関係 があれば 条件判定できる
SELECT * FROM Customer where TIMES >= "2009.11.27" order by TIMES;
SYNTAX
ORDER BY field [(DESC|ASC)][, ...]
DESC
指定したカラムでソートする
-- id, message の順に sort
select * from tbl order by id, message
-- 各項目について ASC DESC を指定する
-- Default は昇順( ASC )
select * from tbl order by id ASC, message DESC
-- where の後でなくてはならない
select * from tbl where id = 1 order by id, message
// 文字列でも Sort 可能 ( ASCII code 順かな ? )
SELECT * FROM member order by age
___
■ GROUP BY
DESC
指定したカラムの値ごとにグループ化する。
POINT
グループ化した後は, sum, avg などの統計関数で値をとる。
-- 性別ごとに平均年齢をもとめる
SELECT sex, AVG(age) FROM member GROUP BY sex;
SYNTAX
INSERT INTO テーブル名 (フィールド名 , フィールド名 ,...) VALUES(値 , 値 ,...);
# Primary ID は 1 から始まる
insert into testtbl (NAME) values("tanaka")
BAD
insert into testtbl ("NAME") values("tanaka")
OK
insert into testtbl (NAME, AGE) values("tanaka", 32);
___
■ UPDATE
SYNTAX
UPDATE [LOW_PRIORITY] [IGNORE] テーブル名
SET field=val [,field=val ...]
[WHERE 条件式]
[ORDER BY ...]
[LIMIT 値]
DESC
レコードを更新します
すべてのレコードを一括更新、もしくは条件式を満たす特定のレコードだけを更新できる
// Table[mn] の ID == 30 の ガス を 3000 にする
UPDATE mn SET ガス = 3000 WHERE ID = 30;
// 複数を指定することもできる
// UPDATE は左から右に 評価する
// [商品番号(id_g)]"3"の[価格(price)] フィールドに"3200"を代入し, 1.05倍
UPDATE goods SET price = 3200, price = price * 1.05 WHERE ID = 3;
BAD
UPDATE mn SET ガス = 111, 水 = 222, WHERE ID =32 ;
OK
UPDATE mn SET ガス = 111, 水 = 222 WHERE ID =32 ;
// String Data は ["] が必須
BAD
UPDATE kabu SET 会社 = aaa WHERE id = 12;
OK
UPDATE kabu SET 会社 = "aaa" WHERE id = 12;
___
■ DELETE
SYNTAX
DELETE from tbl
DESC
レコードを消す。
// 10 才以下は削除
DELETE FROM member WHERE age < = 10;
// 田中さんは削除
DELETE FROM member WHERE name = "tanaka"
// 30 才より下を消す
DELETE FROM member WHERE age < = 30
WARNING
条件を指定しないと全部消える。
DELETE FROM member;
___
■ WHERE
SYNTAX
where condition
DESC
条件を指定する。
SELECT CustomerID, CompanyName, City
FROM Customers WHERE City = 'London'
select * from cmdTbl where ID>=1
// 複数の指定
// 20 代のみ削除
delete from Customer where age >= 20 AND age < = 29;
// C みたいに () もあり
SELECT * FROM customer WHERE (id_c >= 2 AND id_c < =4) OR sex = 1;
BAD
delete from testtbl where ID == 1;
OK
delete from testtbl where ID = 1;
WARNING
条件を指定しないと すべて削除することになるので注意 ( これかなり重要 ! )
where "xxx" [quot] を忘れずに
// あいまい検索
select from アイドル where like "森%千里"
// REGEXP 検索
// 部分にのみ Match すれば OK
//
select from アイドル where regexp "森.千里"
___
■ データ定義
___
■ CREATE DATABASE
SYNTAX
CREATE DATABASE [IF NOT EXISTS] name
DESC
指定した名前のデータベースを作成する
WARNING
IF NOT EXISTS を指定していないときに
既存の DB を指定するとエラーになる
___
■ CREATE TABLE
SYNTAX
CREATE TABLE Customer (
-- 名前 型 属性
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
fullname VARCHAR(40) NOT NULL,
age TINYINT UNSIGNED NOT NULL ,
sex TINYINT UNSIGNED NOT NULL,
email VARCHAR(50),
-- 制約
PRIMARY KEY (id)
);
DESC
Table を作成する
TIP
// into outfile "xxx" がないとだめらしい
// 単独ですると, 落ちる
echo use test;select * from tbl into outfile "foo.csv" fields terminated by ',' \
| mysql -u root -pXXX
CREATE TABLE Customer (
-- 名前 型 属性
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
fullname VARCHAR(40) NOT NULL,
age TINYINT UNSIGNED NOT NULL ,
sex TINYINT UNSIGNED NOT NULL,
email VARCHAR(50),
-- 制約
PRIMARY KEY (id)
);
-- Column の定義
name type [NOT NULL | NULL] [DEFAULT val] [AUTO_INCREMENT]
[[PRIMARY] KEY] [COMMENT 'string'] [reference_definition]
-- 名前 型 属性
-- name 32文字 NULL はなし Default値 "tanaka"
name char(32) NOT NULL DEFAULT "tanaka",
-- INNER JOIN または [,] で 内部結合をする
select mem.name, adr.pref from mem, adr where mem.idadr = adr.id;
select mem.name, adr.pref from mem JOIN adr on mem.idadr = adr.id;
-- INNER を明示しても良い
select mem.name, adr.pref from mem INNER JOIN adr on mem.idadr = adr.id;
WARNING
-- , の場合は ON は使えない。where を使うこと。
select mem.name, adr.pref from mem, adr where mem.idadr = adr.id;
WARNING
-- 結合条件を指定しないと 外部結合による外積の結果になる。
select mem.name, adr.pref from mem, adr;
select mem.name, adr.pref from mem INNER JOIN adr;
// 組み込む前 ( 3 が別テーブルへの ID )
[ A | B | 3 | D ]
// 参照先テーブル
[ 3 | "あ" | "い" | "う" ]
// 組み込み後
[ A | B | "あ" | "い" | "う" | D ]
// ON のかわりに WHERE を使っても良い
SELECT field FROM tblA INNER JOIN tblB WHERE tblA.x = tblB.y
// 結合した Table から
SELECT field FROM tblA INNER JOIN tblB WHERE tblA.x = tblB.y
// さらに絞り込む
and tblA.y = 10;
___
■ 外部結合(OUTER JOIN)
SYNTAX
tblref LEFT [OUTER] JOIN tblref [join_condition]
tblref RIGHT [OUTER] JOIN tblref [join_condition]
POINT
内部結合とは異なり、カラムが一致しない場合も左( または右 )側のテーブルの
全レコードを出力する結合方式。
-- member テーブルを左側にして, 右にアドレステーブルを結合する。
-- 外部結合のキーワードとして LEFT をつけること。
select mem.name, adr.pref from mem LEFT JOIN adr on mem.idadr = adr.id;
-- LEFT キーワードを付ければ外部結合になるため OUTER キーワードは任意。
-- 結果は同じ。
select mem.name, adr.pref from mem LEFT OUTER JOIN adr on mem.idadr = adr.id;
POINT
LEFT, RIGHT の指定は基準となるテーブルを指定する時に使う。
RIGHT は LEFT の別表現のため、覚えるのがメンドイならば LEFT だけを使えばいい。
またDBの移植性を考えると LEFT に統一すること。
-- memer テーブルはレフト, adr テーブルはライト扱いになる。
-- 右扱いのテーブルは一致するカラムが無い場合は NULL が埋められる。
-- 左扱いのテーブルは必ずデータが取得される。
select mem.name, adr.pref from mem left join adr on mem.idadr = adr.id;
-- これは同じ結果になる。 left < -> right を変更してテーブルの指定の指定を切り替えただけ。
-- 基準は memer テーブルのまま。
select mem.name, adr.pref from adr right join mem on mem.idadr = adr.id;
-- これは逆になる。
select mem.name, adr.pref from mem right join adr on mem.idadr = adr.id;
// 次はいれることができる -> 0 が "0" と解釈してくれる
insert into foo (test, str) values(0, 0)
BAD
insert into tbl (test, str) values(0, 0aaa)
OK
insert into tbl (test, str) values(0, "0aaa")
-> ちなみに table 一覧を見ると, ["] はつかない. -> これは 文字列ですよ ! という意味
// [ Default Value ] が空のときは 怒られる
insert into foo (test) values(0)
Field 'str' doesn't have a default value
WARNING
NotNULL を指定すると インサート時のカラムの指定がなければDefault値が設定される。
そのとき値の指定がなければエラーになる。
TEXT, BLOB はデフォルト値をもつことができない為 NotNULL オフではエラーになる。
NotNULL オンではNULLが設定される。
Field 'xxx' doesn't have a default value
// 数値から 書式変換
// String 型になる
// RET: 19,800
mysql> select format( 19800, 0 )
// 文字列から数値に 明示的に変換
mysql> select cast( "100" as signed )
// BAD
mysql> select cast( "100.1" as float )
___
■ 文字列操作
___
■ LPAD
DESC
Left Padding
左に文字を詰める
// RET
// 0000000009
select LPAD( "9", 10, '0' );
select LPAD( id, 10, '0' ) from tbl;
// 数値の文字列を sort する
// 1
// 2
// 11
select id from tbl order by LPAD( id, 10, '0' );
// 1
// 11
// 2
select id from tbl order by id
___
■ concat
select concat("aaa","bbb");
select concat(myoji,namae) from member;
-- カラムのデフォルト値を取得する
select default( idadr ) from member;
___
USAGE >■ USAGE
___
■ MySQLを起動する
DESC
すべては Program であることを忘れないこと
常駐 Program であることを意識する. ( Service > MySQL にはいっている )
Program 本体は
C:\Program Files\MySQL\MySQL Server 5.1\bin\mysql.exe
↑に SQL command を送信することで DB 操作をする ( 今は jsp 経由でなげている )
___
■ DB.を作成する
DESC
MySQLAdminstrator(GUI) でのつくりかた
1. Sel [カタログ]
2. Sel Schema(図表) RMB > Create New Table
Schema > Table という Data 構造らしい
3. Column を入力する
WARNING
名前 (TIME | DESC) は reserved かも
4. Table Name をいれる
5. 作成したものを QueryBrowser で確認する
TIP
Primary Key には KEY Icon が表示される
CHAR() の方が VCHAR よりも軽いらしい
WARNING
CHAR(256) は too big といって怒られる -> '\0' 文字を考慮してね ! ということかな ?
以下の command が生成される
CREATE TABLE `mytbl`.`New Table` (
`ID` INTEGER UNSIGNED NOT NULL AUTO_INCREMENT,
`TOOL` CHAR(128) NOT NULL,
`ARG1` CHAR(256) NOT NULL,
`ARG2` CHAR(256) NOT NULL,
`ARG3` CHAR(256) NOT NULL,
`ARG4` CHAR(256) NOT NULL,
`TIME` CHAR(128) NOT NULL,
`DESC` CHAR(256) NOT NULL,
PRIMARY KEY (`ID`)
)
ENGINE = InnoDB;
// DB の内容を一覧する
// RET: mysql, test ( これが DB 扱いらしい. )
SHOW DATABASES;
// DB を作成する
// ということは ( App ごとに )config.xml に指定するのは, DB の名前かも
CREATE DATABASE testDB;
// DB を選択する
// Window 部分に, localhost:3306/testDB
USE testDB;
// table 一覧をみる
show tables;
// table 作成
create table Customer (
age INT(3),
name VARCHAR(20),
PRIMARY KEY (PREF_CD)
);
USAGE
起動して接続する
( ということは, winsock などを利用して, DB へ SQL command を投げているのか )
DB はひとつの Program( PS )であり, Port 3306 から起動しているのか ?
MySQL > MySQL Query Browser
ServerHost: DB がある場所を指定する
username : Account
Password : xxx
Table を選択する.
USE SampleDB040;
___
■ ユーザー管理
___
■ Password
-- ユーザー xxx が DB ( db_name ) へ接続する際にパスワード認証を必要にする
mysql -u xxx -p db_name
-- Password も Table にある
shell> mysql -u root -pOldPassword
-- "root" user の password を "xxx" にする
mysql> UPDATE mysql.user SET Password=PASSWORD('xxx') WHERE user='root';
-- 反映するには FLUSH PRIVILEGES でサーバに権限テーブルを再読み込みさせる
mysql> FLUSH PRIVILEGES;
___
■ ユーザー 追加
-- 権限テーブルを直接変更する
INSERT INTO user (Host,User,Password) VALUES('localhost','xxx',PASSWORD('yyy') );
FLUSH PRIVILEGES;
-- すべての DB の操作権限をもつ ユーザ (xxx) を パスワード ( yyy ) で追加
GRANT ALL PRIVILEGES ON *.* TO xxx@'%' IDENTIFIED BY 'yyy' WITH GRANT OPTION;
-- user( xxx ) を作成する。
CREATE USER xxx;
-- パスワード( yyy )を指定
CREATE USER xxx IDENTIFIED BY "yyy";
-- user( xxx ) を削除する。
DROP USER xxx;
-- 名前を変更する
RENAME USER xxx TO yyy;
-- パスワードを変更する
SET PASSWORD FOR yyy = PASSWORD( "zzz" );
POINT
操作権限を与えるには GRANT 命令を使うこと。
___
■ grant
SYNTAX
GRANT priv_type [(column_list)] [, priv_type [(column_list)] ...]
ON {tbl_name | * | *.* | db_name.*}
TO user_name [IDENTIFIED BY [PASSWORD] 'password']
[, user_name [IDENTIFIED BY [PASSWORD] 'password'] ...]
[REQUIRE
NONE |
[{SSL| X509}]
[CIPHER cipher [AND]]
[ISSUER issuer [AND]]
[SUBJECT subject]]
[WITH [GRANT OPTION | MAX_QUERIES_PER_HOUR # |
MAX_UPDATES_PER_HOUR # |
MAX_CONNECTIONS_PER_HOUR #]]
DESC
ユーザを作成したり、ユーザーに操作権限の追加、削除をする。
MySQL ユーザ名には最大 16 文字
Unix ユーザ名は通常 8 文字まで
MySQL で認証目的に使用するパスワードは
Unix ユーザ名(ログイン名)や Windows ユーザ名とは関係ない
MySQL クライアントはデフォルトで
現在の Unix ユーザ名を MySQL ユーザ名としてログインしようとするが
これは利便性のためだけのこと
MySQL で認証目的に使用するパスワードは
Unix ユーザ名(ログイン名)や Windows ユーザ名とは関係なく自由に設定できる。
クライアントプログラムで -u || --user により別の名前を指定できる
これは
すべての MySQL ユーザ名にパスワードを設定しないと
データベースを安全に保てないことを意味する
WARNING
パスワードを設定しないと
だれでも任意の名前でサーバへの接続を試みることができ
パスワードのない名前を指定すれば接続できてしまう
-- ユーザー権限をみる
show grants
show grants for root@localhost
-- ユーザー xxx へ全権限を与える
GRANT ALL ON *.* TO xxx
-- SELECT のみを許可する。
GRANT ALL select *.* TO xxx
-- すべての権限をなくす
revoke ALL select *.* FROM xxx
-- データベースを指定するか
use xxxdb;
-- テーブルの前に明示する。
select * from xxxdb.table;
___
■ 1075
MSG
there can be only one auto column and it must be defined as a key
DESC
Primary Key がないと言われる
Message: テーブルの定義が違います;
Auto increment && Primary Key OFF にすると言われるらしい
[ KEY ] mark をつけるのが POINT
___
■ 1048
ERROR 1048 (23000) at line 32: Column 'name' cannot be null
DESC
NOT NULL 属性の Column に null をいれようとした
CREATE TABLE tbl (
name char(32) NOT NULL,
age INT NOT NULL
);
-- insert tbl (name,age) values(null,20);
insert tbl (name,age) values("suzuki",20);



 _
_ _
_ _
_